
You have read the guides. You know AI can personalize at scale, generate content faster, and optimize campaigns automatically. You have probably tried at least one tool that was supposed to change everything. It did not. The problem is not that AI marketing does not work. The problem is that every guide explaining it was written by someone selling it. I have spent 14 years running actual campaigns for retail, FMCG, and BFSI brands, then building and evaluating AI tools. Here is the honest version of this topic: where it works, where it fails, and what no vendor-funded guide will say out loud.
AI Marketing vs. Marketing Automation: The Distinction Nobody Explains Clearly
Most teams treat AI marketing and marketing automation as interchangeable. If you use HubSpot workflows, you have probably been told by now that the AI features inside that platform are just the next evolution of what you already do. Vendors encourage this. It keeps the upsell clean.
The problem is that conflating these two things is the first and most consequential implementation error a marketing team can make. It is not a semantics problem. It is an architecture problem.
Marketing automation runs on rules. If a contact opens an email, trigger a follow-up. If a lead scores above 80, notify sales. If a cart is abandoned, send a recovery sequence. The logic is deterministic: the system executes exactly what you programmed it to execute, every time. The intelligence is yours. The system is the executor.
AI marketing runs on probability. Given everything we know about this person, their behavior, their history, their position in the lifecycle, what is the most likely next best action, content, or message to move them forward? The system is not executing your rules. It is making predictions about what your rules should be. That is a fundamentally different relationship between the marketer and the machine.
The performance benchmarks for automation workflows that incorporate AI decision layers versus those that do not are covered in marketing automation with AI statistics. The gap is not marginal.
When a team conflates these two layers, here is what happens in practice. They buy an AI personalization tool and plug it into their existing automation framework. The AI produces next-best-action recommendations. The automation layer receives them and either cannot act on them, because the workflow was built for broadcast not conditional branching at that granularity, or ignores them in favour of the predetermined rule. The AI runs. Nothing changes. The team concludes that AI marketing does not work. The more accurate conclusion is that they deployed a prediction engine into a rules engine and expected the two to do the same job.
Map your current automation architecture before you evaluate any AI marketing tool. Mark every decision point that is currently rule-based. Those are your AI opportunity zones. The question is not whether to replace automation with AI. It is where adding prediction to your execution layer will produce better downstream outcomes than a rule ever could.
Gartner’s research on AI marketing maturity documents this as a staged progression. Stage 1 is rule-based automation: systems follow pre-programmed if-then logic with no learning capability. Stage 2 introduces task-specific AI handling discrete functions. Stage 3 and beyond involves AI agents coordinating decisions across your full marketing stack. Organizations that skip Stage 1 mastery and attempt to deploy Stage 3 capabilities consistently report the same outcome: the complexity overwhelms teams that lack foundational data infrastructure. The maturity stages are sequential, not optional.
What Marketing Automation Actually Does (and Where It Stops)
Marketing automation is a trigger-and-action system. It executes sequences you designed based on conditions you defined. Done well, it removes human bottlenecks from repetitive execution and ensures consistent follow-through across every contact in your database.
What it cannot do is learn. A workflow that sends a welcome email three hours after signup sends that email to every signup, regardless of whether that person is a highly engaged enterprise buyer who visited your pricing page four times or a student who downloaded a free resource and will never convert. The rule applies uniformly. The outcome varies enormously. Automation has no mechanism to notice the difference and adjust.
For a full definitional treatment of what AI marketing is, including its component technologies and how it differs from earlier generations of marketing software, that chapter covers the ground in depth.
Where AI Marketing Takes Over
AI marketing’s job is precisely the gap automation cannot fill: identifying which version of the experience is most likely to produce the best outcome for this specific person, at this specific moment, given everything the system knows about them.
This is where the architecture distinction becomes practical. AI is not a replacement for your automation layer. It is a decision layer that sits above it. Your automation still executes. But the inputs to those decisions, which message, which timing, which offer, which channel, are determined by a model rather than a rule. The model updates as it observes outcomes. Your rules do not.
Read next: marketing automation vs AI marketing
The distinction above sets up the harder question: under what conditions does the AI decision layer actually work? That is where most teams get it wrong, and where most vendor guides look away.
Where AI Marketing Actually Works: The Four Conditions
Teams adopt AI marketing tools based on vendor use cases. AI for email personalization. AI for predictive lead scoring. AI for content generation. The assumption is that the tool creates the conditions for those use cases to function. It does not. The conditions have to exist first. When they do not, the model runs and produces output that looks like intelligence but does not compound into performance.
I call this the Readiness Floor: the baseline of data infrastructure and team capability below which AI marketing tools will not improve regardless of how good the feature set is. Below that floor, you are not running AI marketing. You are running an expensive simulation of it.
The Readiness Floor has four conditions:
- Data volume: The AI model needs enough historical outcomes to find meaningful patterns. Without sufficient transactional or behavioral history, the model cannot distinguish signal from noise.
- Data quality: Clean, consistent, well-labeled data. Fragmented data from disconnected sources, inconsistent tagging, or missing attribution breaks the model’s ability to learn from outcomes even when volume is sufficient.
- Feedback loop: The system must be able to observe what happened after it made a recommendation. Did the predicted high-propensity contact convert? Did the next-best-action email produce a click? Without this loop closed, the model cannot update and the AI’s output degrades to a static score rather than a compounding intelligence.
- Organizational readiness: Someone on your team must have the judgment to act on probabilistic recommendations. AI outputs a recommendation with a confidence level. A team without the context to evaluate that recommendation will either override it reflexively or act on it blindly. Both produce bad outcomes.
This is not a theoretical problem. Salesforce’s 2024 State of Marketing report surveyed 4,850 marketing decision-makers and found that 41% cite incomplete or siloed data as their primary blocker to AI adoption, ahead of budget constraints, skills gaps, and compliance concerns. The data condition is the most common failure point and the least discussed in vendor onboarding.
The data on where AI adoption is actually happening versus where teams report seeing results is worth checking before you benchmark your own stack. The gap is documented in AI adoption in marketing statistics.
The Data Problem Most AI Marketing Vendors Don’t Mention
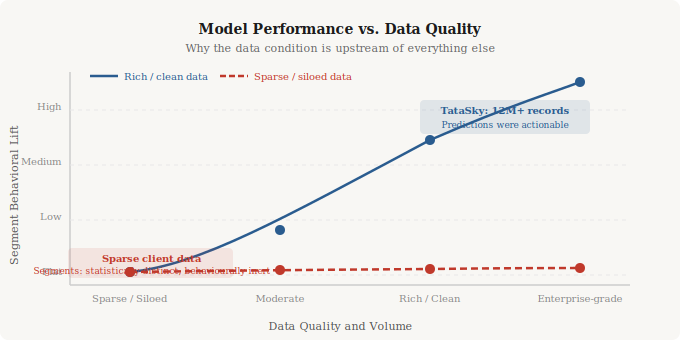
Working at Hansa Cequity, I spent two years inside the customer data of large retail and FMCG brands. We ran propensity models, RFM segmentation, churn prediction, and campaign attribution across clients including TataSky (12M+ customer records) and Westside’s ClubWest loyalty programme (2.7M members). The model quality gap between clients with clean, longitudinal transactional data versus clients with fragmented or low-volume data was not marginal.
Propensity models built on TataSky’s data produced meaningfully differentiated segments. The predicted high-value customers behaved like high-value customers. The predicted churners churned at rates that validated the model. The predictions were actionable because the underlying data was rich enough for the model to find real patterns.
The same modelling approach applied to a client with sparse or inconsistent data produced segments that were statistically distinguishable but behaviourally inert. The predicted high-value segment did not outperform the predicted low-value segment in conversion. The model had found patterns in noise rather than patterns in signal. No amount of algorithmic sophistication closes that gap. You cannot model your way out of a data problem.
Most AI marketing vendors will onboard you regardless of whether your data infrastructure meets this condition. Their revenue comes from contracts, not from your model performance. The data readiness check is yours to do.
Why Most AI Marketing Fails Without a Feedback Loop
The feedback loop condition is the most commonly skipped and the least discussed.
Here is the mechanism. An AI model makes a recommendation: send this message to this person at this time because the model predicts it will produce a click or a conversion. The automation layer executes. The outcome happens, or does not happen. For the model to improve, it needs to observe that outcome and update its parameters accordingly.
When the feedback loop is not closed, when the model’s recommendation executes but the outcome data does not flow back to the model, the AI operates on its initial training data indefinitely. It does not learn. The predictions become increasingly stale as customer behaviour shifts. After six months, the team reviews performance, sees no improvement, and concludes that the AI tool did not work. The AI did exactly what it was designed to do. The loop was never connected.
The tool does not create the conditions for AI marketing to work. The conditions must exist before the tool is deployed.
Before evaluating any AI marketing tool, apply the Readiness Floor check honestly. Score each of the four conditions. Do not proceed to tool selection until at least three of the four are met. If fewer than three are present, the return on fixing the data infrastructure will exceed the return on adding a tool to broken foundations.
That is the conditions problem. The next problem is what happens when teams skip the check and deploy anyway, at scale, in public.
The Documented Failures: What AI Marketing Gets Wrong at Scale
The marketing industry has a consistent narrative about AI failures. A few brands moved too fast. They did not QA the output. The tech was not ready for that use case. Learn from them, but do not overweight them. These are edge cases on an otherwise upward curve.
I have looked at the public record of documented AI marketing failures across the last three years and that framing is wrong. The failures do not follow a random distribution. They cluster into three categories, and each category maps to a specific condition that, if assessed in advance, would have predicted the failure. The pattern is repeatable. The edge case narrative is convenient for the companies selling the tools.
Here are the cases.
McDonald’s AI drive-through, deployed with IBM, failed on order comprehension at volume and was decommissioned in 2024. Customers received incorrect orders. The system suggested quantities like 300 McNuggets. The failure category: natural language understanding deployed without sufficient training data on the variation of real-world order inputs at that volume. This is a data volume and data quality failure. The Readiness Floor condition was not met before deployment.
Meta Advantage+ creative override: Marketing Brew reported in April 2026 that agencies and brands found Meta’s AI generating new visuals and overriding creative decisions already made, even after opting out of AI features. One agency documented that AI features “re-enable themselves, generate new visuals, and override decisions that were already made.” A Meta spokesperson confirmed advertisers can opt out, but multiple advertisers reported difficulty locating the correct toggles. The failure category: automation autonomy failure. The system was given an optimization target without adequate guardrails on what inputs it could modify. Advertisers who had built winning creative found it replaced by a model optimizing for a platform metric, not a brand.
Toys R Us AI brand film, shown at Cannes 2024, generated with OpenAI’s Sora and described by a Fast Company senior editor as an “abomination.” The Coca-Cola AI Christmas ad, pulled in the Netherlands after audiences described it as “soulless.” The failure category: emotional authenticity failure. AI optimized for visual coherence. It cannot encode the affective associations that human audiences apply to nostalgic brand territory. The creative looked right. It felt wrong. That gap is not a QA problem. It is a structural limitation of what generative AI is actually optimizing for.
The Sports Illustrated AI author scandal, AI-generated articles attributed to fictitious authors with the CEO of the operating entity terminated after exposure, is a different category: deployment without transparency. The tool worked. The editorial judgment and governance layer was absent.
The full catalogue of implementation risks, bias, data privacy, creative override, reputational exposure, is mapped in AI marketing risks. But the cases above point to a specific mechanism that risk catalogues tend to miss.
The failure pattern in AI marketing is not a cautionary tale about a few brands moving too fast. It is a repeatable outcome when AI is deployed without a human checkpoint at the decision boundary, and the content industry selling the tools has a financial interest in calling it an edge case.
The Three Failure Categories That Appear Repeatedly
Pull back from the individual cases and the pattern is clear.
Natural language and comprehension failures happen when AI is deployed on tasks requiring nuanced understanding of real-world input variation, customer orders, support queries, freeform text, without sufficient training data on the actual distribution of that variation. McDonald’s drive-through is the canonical example. The fix is not better AI. It is data volume and quality assessment before deployment.
Automation autonomy failures happen when AI is given an optimization target without guardrails on what it can modify to hit that target. The system optimizes efficiently and correctly. The optimization destroys something the brand valued that was not in the objective function. Meta Advantage+ creative replacement is the canonical example. The fix is a clearly defined Decision Boundary: the AI can optimize within this envelope, and any change outside it requires human approval.
Emotional authenticity failures happen when AI generates brand-facing creative for contexts where emotional resonance is the primary success criterion. AI optimizes for coherence and surface-level quality signals. Human audiences evaluate creative against their accumulated emotional associations with a brand. These are different optimization targets. The fix is not better generative AI. It is keeping a human creative director at the decision boundary for any work where the brand’s emotional register is at stake.
The Decision Boundary: the point at which an AI system’s output becomes a brand’s public action, and the required checkpoint for human judgment before that output ships. Identifying this boundary for every AI application before deployment is the single most practical thing a team can do to avoid the failure categories above.
Knowing where AI fails is half the picture. The other half is what it actually looks like when it works, at a real team’s scale, on a real Monday morning.
What AI Marketing Actually Looks Like for a Real Team
Teams begin AI marketing implementation by chasing the most impressive use cases. Full campaign automation. AI-generated creative at scale. Predictive revenue modeling. These are the use cases vendors lead with at conferences and in case studies. They are also the ones that require the most data infrastructure, the longest feedback loops, and the highest organizational readiness to produce results.
The Execution Gap: the distance between AI marketing as a category of tools and AI marketing as a workflow a real team can ship, measure, and compound. This gap is where most implementation plans collapse. Not because the technology is wrong. Because the entry point is wrong.
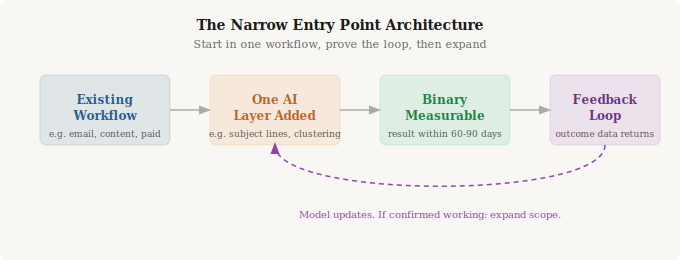
Working on SEO and content-led growth at GrowthMentor for roughly three years, I did not begin AI integration with automated content generation or AI-driven campaign management. The first AI application was keyword clustering and content gap analysis: using AI tooling to identify opportunities the human research process was missing, systematically, at a scale that manual analysis could not match. The model’s job was narrow and specific. The feedback loop was already in place: we could observe rankings movement and traffic to those pages within 60 to 90 days. The output was a binary measurable outcome.
That worked. Then scope expanded. The same pattern at KoinX, where I run SEO and content strategy for a crypto tax SaaS with 1.5M+ users: the first AI application was brief acceleration and content gap analysis, not content generation. The editorial judgment layer was already functioning. The AI compressed the research-to-brief cycle. It did not replace the process. Starting narrow is not a limitation. It is the architecture that makes compounding possible.
The first AI application should not be the most impressive one. It should be the one most likely to prove the feedback loop in 60 days.
The Right Entry Points for a Team Without a Data Science Function
Most of the target readership does not have a data science function. That is not a blocker. It is a scope filter.
The AI marketing applications that work without extensive data infrastructure are also, not coincidentally, the ones most likely to produce measurable results within 60 to 90 days.
Email subject line testing with AI-assisted variant generation. Platform-native paid media bid optimization (Google Smart Bidding, Meta Advantage+ bid strategy, distinct from creative autonomy). Content brief acceleration using AI research tools layered onto an existing editorial process. Customer segmentation using platform-native AI scoring inside your existing CRM, not a custom-built model. Social posting time optimization using platform analytics.
None of these requires a data science hire. All of them have feedback loops built in: open rates, ROAS, traffic, conversion, engagement. All of them produce a binary measurable outcome within a timeframe that lets you validate the model before expanding scope.
The ambitious use cases, full campaign automation, AI-generated creative at scale, predictive CLV modelling, are not off the table. They are the second or third application, after you have proven the feedback loop and built organisational readiness through one or two narrow wins.
Honest Cost Framing: What AI Marketing Actually Requires in Time and Budget
The cost question is almost entirely absent from AI marketing hub pages. Here is the honest version.
Platform-native AI features, Google’s Smart Bidding, Meta’s bid optimization, HubSpot’s predictive lead scoring at certain tiers, email send-time optimization in most email platforms, are already included in tools you are probably paying for. The cost is zero incremental spend. The cost is the time to configure them correctly and close the feedback loop.
Specialist AI marketing tools, AI content brief generators, AI SEO tools, AI copywriting assistants, run from roughly $50 to $500 per month depending on the tool and team size. Most mid-market teams need two or three of these at most.
Enterprise AI infrastructure, custom models, AI personalization engines like Dynamic Yield or Movable Ink, full marketing AI platforms, is materially more expensive and requires data infrastructure that most teams reading this do not yet have. This is not the entry point.
The honest total for a growth-stage or mid-market team starting with AI marketing correctly: likely $100 to $300 per month in incremental tooling, plus the cost of internal time to configure, monitor, and maintain the feedback loop. The ROI question is meaningful only after the feedback loop is confirmed working, at which point it becomes a compounding return rather than a flat expense.
Read next: how to implement AI in marketing
Where to Start: A Five-Step Diagnostic
- Audit your current marketing automation layer and mark every decision point that is currently rule-based. Those are your AI opportunity zones: the places where a prediction would produce a better outcome than a uniform rule.
- Apply the Readiness Floor check to each opportunity zone. Score data volume, data quality, feedback loop, and organisational readiness honestly, met or not met. Do not proceed to tool evaluation in any zone where fewer than three of the four conditions are met.
- Identify one workflow that already has a feedback loop and a binary measurable outcome within 60 to 90 days. That is your first AI application. Not the most interesting one. The one most likely to prove the model quickly.
- Map the Decision Boundary for that workflow: the point at which the AI’s output becomes something a customer sees or experiences. Put a human checkpoint at that boundary before you ship anything.
- After 60 days, review the feedback loop data. Did the AI output compound, did performance improve as the model observed more data? If yes, expand scope. If no, diagnose which Readiness Floor condition was missing before adding another tool.
If you want help auditing your current stack against these criteria, reach me at shankar@shno.co.