
Most articles on AI personalization in marketing tell you the same things: machine learning, real-time adaptation, Amazon, Netflix. You already know this. What you actually want to know is whether it works at your scale, with your data, and where to start. That question goes unanswered in most guides. Because the honest answer is that AI personalization works when the data is ready, and fails quietly when it is not. I spent years building CRM and loyalty strategy for brands like Westside, TataSky, and Axis Bank. This is what it actually requires, and where a non-enterprise team should start.
What AI Personalization Actually Does (And What It Needs to Do It)
Most explanations of AI personalization describe what the output looks like. A personalized subject line. A product recommendation grid. A homepage that adapts based on your last visit. This is the end of the pipeline. And it is the least useful place to start understanding it.
The reason most teams are evaluating AI personalization is legitimate. 71% of consumers expect personalized experiences from the brands they interact with. Companies that lead in personalization generate 40% more revenue from it than average performers. But evaluating AI personalization by its outputs means you evaluate platforms by their demos. Demos always look good. They are built to look good. The data behind them is clean, abundant, and pre-formatted to show the system at peak performance. Your customer data almost never looks like that.
Here is what the demo does not show you. Every AI personalization system runs on a feedback loop. It takes input data, identifies patterns, makes a recommendation, observes the outcome, and adjusts. The quality of the output is entirely determined by the quality of the input. A model trained on sparse, fragmented, or stale data produces sparse, fragmented, or stale recommendations. The technology is not the variable. The data is.
I ran subscriber preference modelling for TataSky across 12 million-plus customer records. The model architecture was identical across the entire base. The output quality was not. Segments with rich behavioral history, call patterns, content consumption data, service interaction logs, produced coherent and actionable predictions. Segments with sparse interaction records produced outputs indistinguishable from random defaults. Same code. Same system. Completely different results, determined entirely by what signal existed in the data.
Before you open a single platform demo, map what you actually have against three things: behavioral history (what customers have done and when), contextual signal (where, on what device, at what lifecycle stage), and pattern volume (enough repetitions of each behavior for the model to find signal rather than noise). That mapping tells you more about your AI personalization readiness than any vendor pitch. The current benchmarks on revenue lift, conversion performance, and consumer expectations are compiled in the AI personalization statistics, which is worth checking before building any internal business case.
AI personalization is not a feature you switch on; it is a feedback loop that produces better outputs only when fed inputs with enough signal to learn from.
The Three Inputs the AI Is Actually Learning From
Every AI personalization system needs three data layers to function. Understanding them changes how you assess your own readiness.
The first is behavioral history. Not demographic data. Not customer attributes. What the customer has actually done: pages visited, emails opened, products viewed, items purchased, support tickets raised. This is the raw material the model learns from. Without sufficient behavioral history per customer record, the model has nothing to generalize from.
The second is contextual signal. The same behavior means different things in different contexts. An email open at 9 a.m. on a weekday tells a different story than the same open at 11 p.m. on a Sunday. A product view from a first-time visitor is a different signal from the same view from someone who purchased twice last year. Context is what gives behavioral history its meaning. Without it, the patterns are flat.
The third is pattern volume. An AI model does not learn from one example. It learns from enough repetitions of a behavior to distinguish signal from coincidence. What counts as enough depends on the channel and the decision being made. But below a minimum volume, the model is not personalizing. It is guessing with extra steps.
Why AI Personalization and Rule-Based Personalization Are Not the Same Problem
Most marketing teams already do some form of personalization. If a customer has not purchased in 90 days, send a re-engagement email. If a customer is in the top loyalty tier, include the premium offer. These are rule-based decisions. You write the logic. The system executes it.
AI personalization works differently. Instead of you writing the decision logic, the system learns the decision logic from behavioral patterns in your data. It identifies which combination of behaviors predicts a purchase, which content variations drive re-engagement for which segments, which timing produces the highest conversion for which customer type. Then it updates those rules continuously as behavior changes.
The practical difference is not just sophistication. It is data dependency. A rule-based system can function on low-signal data because a human wrote the rules. An AI system cannot function below its data floor because the system learns its rules from the data. If the data does not carry enough signal, there is nothing for the model to learn from. This is why the two systems require completely different readiness conversations before you build one.
Why Most AI Personalization Fails Before You Buy a Platform
The standard path most teams take looks like this. They read about AI personalization. They get a vendor pitch. They watch the demo. They sign the contract. They point the platform at their customer data. Then they wait for results. Step four is where it quietly breaks for most teams.
Most AI personalization failures are not technology failures; they are data readiness failures that happen before anyone buys a platform.
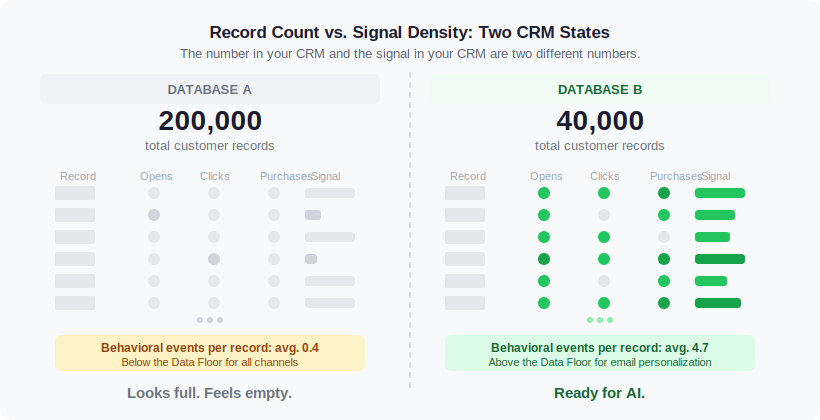
Every AI personalization system has what I call a Data Floor: the minimum viable combination of data quality, behavioral history, and interaction volume required before the system produces output meaningfully better than a rule-based default. Below that floor, the model either mirrors what a simple rule would have done anyway, defaults to population-level averages, or produces recommendations that are technically personalized and operationally useless. The vendor demo does not show you this. Demo environments use clean, pre-enriched datasets built to demonstrate capability. A Gartner survey found that 63% of digital marketing leaders still struggle with delivering personalized experiences, and Gartner’s own recommendation to those teams was to leverage existing data before committing to new platforms. The platforms are not the problem. The data is.
The clearest example I have comes from working with Westside’s ClubWest loyalty programme. 2.7 million members. Years of transaction history. A fully built CRM infrastructure. On paper, the data situation looked rich.
When we dug into the lapsed member segment, 73% of recent lapsers were on DND. Unreachable by SMS. 63% had not opened a single email in the preceding months. The CRM was fully populated. For the purposes of any AI personalization model, it was almost entirely empty of usable behavioral signal.
Pointing a platform at that data would have produced personalized noise at scale. Personalized subject lines on emails nobody opens. Behaviorally targeted SMS messages blocked at the carrier. The technology would have been functioning exactly as designed. The output would have been worthless.
What worked was going around the data problem. We built a Facebook Custom Audience from the lapsed member base and ran re-engagement in their social feed, bypassing the channels where the CRM data had failed us entirely. The campaign worked. It won a CMO Asia Award for Best Use of Facebook. The lesson was not that Facebook is a better channel. The lesson was that the data was not ready for AI personalization and the right move was to find a different approach, not buy a more sophisticated platform.
Before evaluating any platform, run three diagnostic questions against your current data: what percentage of your customer records have at least three distinct behavioral events attached to them in the last 12 months? What is the most recent behavioral event for your median customer record? Are your customer identifiers consistent enough to join data from different channels into a single profile?
If the answers are “under 40%,” “over six months ago,” and “no,” your data is not ready for AI personalization to produce signal above baseline. The right move is not a better platform. It is a data audit.
The research on data quality in marketing consistently shows that fragmented or low-signal data is the most commonly cited barrier to personalization performance across both enterprise and mid-size teams. The gap between what the marketing personalization statistics promise and what most teams actually experience traces almost entirely to this: they buy the platform before checking whether the data can carry the signal.
The Data Floor: What Your Data Actually Needs Before This Works
When most teams hear about AI personalization, they gravitate toward the highest-visibility application. Dynamic website content. Real-time product recommendations. Ads that adapt to individual intent signals in real time. These channels also have the highest Data Floors.
Website personalization requires enough traffic and enough behavioral events per visitor to train a model meaningfully. Product recommendation engines require purchase history data with sufficient breadth, recency, and catalog depth. Ad personalization requires audience scale and signal richness that most mid-size businesses do not have at the data layer. Starting with the most impressive-looking channel when your data sits below that channel’s Data Floor produces underwhelming results. Teams often conclude that AI personalization does not work for businesses their size. That is not the right conclusion. They started in the wrong channel.
I saw this pattern repeatedly in FMCG analytics work at Hansa Cequity, across categories from beverages to personal care. A brand would arrive with distributor data, retailer sell-out data, loyalty card history, and patches of digital engagement data. None of it joined cleanly. The instinct was always to build the most sophisticated model the data theoretically allowed. Multi-source propensity scoring. Composite segmentation across four data streams. The output was consistently at baseline because the signal was not in the data. What worked every time was simpler: identify the single source with the cleanest behavioral history, build one constrained model against that source, produce one clear output. That result was always more useful than the sophisticated model built on fragmented inputs.
Personalization investments that are properly resourced drive 10 to 15% revenue lift on average, per McKinsey’s Next in Personalization research, with leaders in the category reaching 25% or more. The gap between those numbers and most teams’ actual results is almost entirely explained by the data floor problem.
The Data Floor: the minimum viable combination of data quality, behavioral history, and interaction volume required before an AI personalization system produces output meaningfully better than a rule-based default.
Map your available data against the channel-specific thresholds below before choosing your starting channel. The goal is not to start with the channel that excites you most. The goal is to start where you already have data above the floor.
The CRM marketing statistics include current benchmarks on the gap between CRM record volume and the actionable behavioral data those records actually contain, which is useful context before reading the table below.
Data Floor Thresholds by Channel
Most non-enterprise teams reading this will find themselves above the floor for email and below it for everything else. That is not a problem. That is your starting point.
Where to Start When Your Data Is Not Perfect
Two failure modes are equally common here. The first is waiting until the data is perfect before doing anything, which means never starting. The second is going straight to website or product recommendation personalization because those demos looked the most impressive. Both paths produce the same result: no proof of concept, no internal momentum, and nothing learned.
Perfect data is a direction, not a destination. The teams that build real personalization capability move faster because they find their cleanest existing data asset, run one constrained experiment against it, get a real result, and use that result to build the case for the next investment. The cleanest data asset in most non-enterprise marketing stacks is email behavioral data. Which makes email the right first channel.
Working across BFSI clients on lifecycle email campaigns, a behaviorally segmented send to lapsed customers who had previously engaged with a specific product category consistently outperformed unsegmented broadcast re-engagement messages. The segmentation was not sophisticated by any AI standard. It was behavioral history used deliberately: who clicked what, when, and in what product context. Open rates in the behaviorally segmented cohort ran around 31% against 18% in the unsegmented broadcast. That lift was not produced by a platform. It was produced by using existing behavioral data to make one better decision about who gets which message. That result, documented internally, becomes the foundation for the AI personalization business case.
The right first move in AI personalization is not the channel you are most excited about; it is the channel where your data is already cleanest.
The customer retention statistics include documented retention uplift from behavioral segmentation at different list scales, which is useful as a benchmark for what a well-run first experiment should aim to produce.
Why Email Has the Lowest Data Floor
Email has a lower Data Floor than any other personalization channel for three specific reasons.
The identifier is already matched. Email address is the primary key across every interaction in your system. You do not need to solve a cross-device identity problem or maintain cookie consistency across sessions. The record joins itself. Identity resolution is a significant engineering problem for website and ad personalization. For email, it is not a problem at all.
The signal threshold is achievable. Three behavioral events per record, over 12 months, is enough to produce a meaningful segmentation. That is not a demanding requirement for any reasonably active list. Website personalization requires persistent session tracking and traffic volumes most mid-size teams do not have. Product recommendation engines require product interaction depth that takes time and catalog scale to build.
The feedback loop is the fastest available. Email iteration cycles are days. You send, you measure, you learn, and you adjust the following week. Website content model training takes weeks of traffic accumulation before results are interpretable. Recommendation engine optimization takes months. Starting with the channel where you can run a test, see a result, and act on it within the same week is not a strategic compromise. It is the fastest path to learning something real about your data and your audience.
Here is how to confirm your data is ready before you spend anything.
- Pull your customer database and count what percentage of records have at least three distinct behavioral events attached to them in the last 12 months. This is your signal density. If it is under 40%, your first task is improving what you already collect, not buying a new platform.
- Isolate your email list specifically. Count how many subscribers have an open, a click, or a purchase event in the last six months. That number is your minimum viable personalization audience for a pre-platform experiment.
- Split that list into three behavioral groups: engaged in the last 90 days, lapsed but active within the past year, and cold. Send a differentiated version to each. Measure whether the segments responded differently. If they did, you have confirmed behavioral signal in your data.
- Document that result before any vendor conversation. If the segments responded differently, you have a proof of concept. Bring it into your first platform demo and ask the vendor how their system would have improved on it. That single question changes every demo.
- Only after steps one through four produce a clear result: evaluate platforms against your confirmed data reality, not against a demo environment built on someone else’s clean data.
For current benchmarks on what good signal density looks like across company sizes, the AI personalization statistics page is the right place to start.