
You build the segments. The AI does its thing. Six clusters appear on screen. And then you sit there wondering what you are actually supposed to do next. That is not a data problem. That is an activation problem. It is why most AI segmentation projects produce a great-looking model and zero campaign lift. I have spent years building segmentation for brands with millions of customers: a 2.7 million member loyalty programme at Westside, 12 million records at TataSky, store segmentation at Titan Eye+. The model was never the hard part. Knowing what to do with it was.
Your Data Is the Argument. Make Sure It Can Hold One.
Most teams treat data readiness as a binary: either you have a CRM or you do not. If it is populated, you are ready. They connect the platform, export the contacts, and let the model run. Whatever the algorithm finds, they will work with.
This assumption leads to a specific failure: segments that are statistically tidy and commercially useless. The model is not lying to you. It is finding real patterns in the data you gave it. The problem is that the data you gave it did not contain the signals that matter.
AI clustering algorithms group customers who behave similarly. That sounds straightforward until you consider what “behave similarly” means when your dataset is thin, siloed, or weighted toward demographic fields rather than behavioral ones. A customer who bought twice in 18 months and a customer who bought twice last month can look identical in a dataset that only records transaction count. The model groups them together. The model is not wrong. The data did not give it the information to tell them apart.
According to Madgicx’s research on machine learning for customer lifetime value, you need at least 1,000 customers with purchase history and 6 to 12 months of transaction data to build a reliable prediction model. Below that volume, the clusters shift significantly with small additions of new data. You are not building an audience. You are decorating noise.
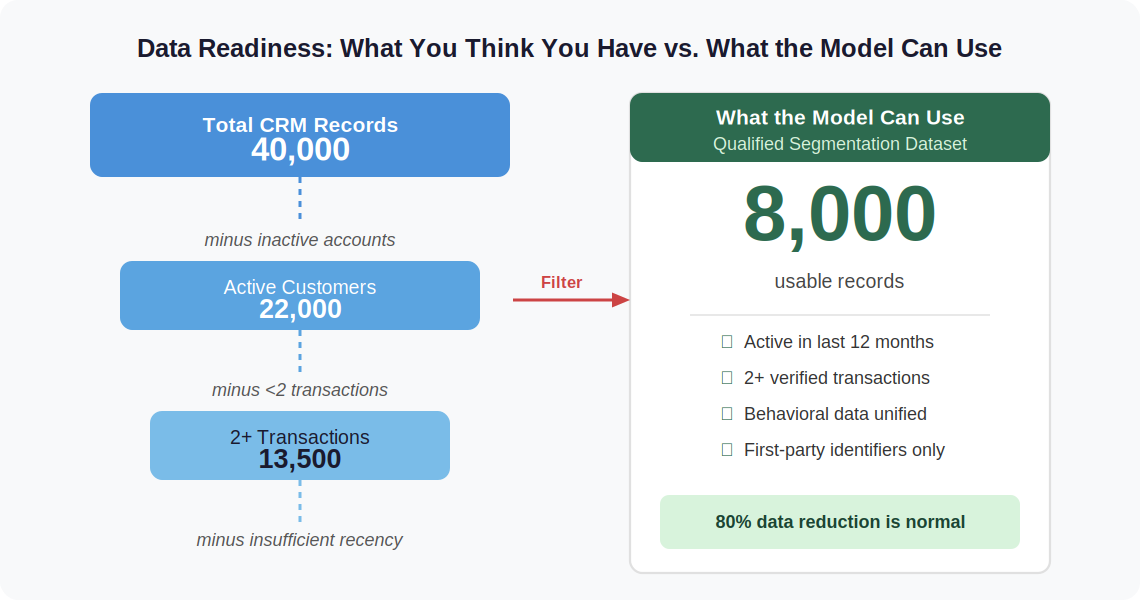
I ran a data audit for a mid-size retail client that had 40,000 CRM records and assumed they were ready for AI segmentation. Once we applied basic qualification criteria, active status, at least two transactions, and sufficient recency, the usable dataset was under 8,000 records. That changed the entire method choice. We moved from clustering to RFM, built three clean segments (active buyers, at-risk, and lapsed), and executed campaigns against each. Those campaigns generated lift. The clustering exercise would have generated a slide deck.
Before importing a single customer record into any AI tool, run a data readiness audit. Count your qualified records: customers with at least two transactions in the past 12 months. Check whether your behavioral data, web activity, email engagement, and app usage, sits in the same place as your transaction data. If they are in different systems with no integration, the model will work with demographic shells rather than behavioral humans. Confirm how much of your data depends on third-party identifiers that could break. These three questions determine whether you are ready to run clustering or whether you should start with something simpler.
Before building a high-value segment, it helps to know what lifetime value benchmarks look like in your category. customer lifetime value statistics give you a reference point for calibrating whether the model’s outputs are commercially realistic for your industry.
RFM Is Not a Fallback. It Is a Starting Point.
There is a persistent assumption in AI marketing content that RFM is the old way and machine learning clustering is the upgrade. This is not how segmentation maturity actually works.
RFM (Recency, Frequency, Monetary) is not a lesser method. It is the right method for a specific data context: teams with fewer than 1,000 qualified records, siloed data, or a need to run their first campaign within weeks rather than months. It produces three to five segments that can be described in plain language to any stakeholder and that map directly to a campaign type without a data science translation layer.
Machine learning clustering adds value when you have volume, behavioral depth, and enough campaign history to validate whether the clusters are predictively stable over time. It is not an upgrade from RFM. It is what you graduate to once RFM is working and your data can support the additional complexity.
The right model is not the most sophisticated model. It is the one your data can actually support.
The data question establishes whether you can build segments worth using. The next question is whether you have been building segments worth using at all.
The Segment Graveyard: Why Most AI Projects Stop at the Clusters
There is a standard project sequence that most AI segmentation work follows. The team gets access to a tool, imports customer data, runs the model, receives a set of clusters, presents them to stakeholders, and calls the segmentation complete. Six audiences now exist. The work is done.
AI customer segmentation fails most marketing teams not because the models are wrong, but because the segments were built before anyone decided what to do with them.
A segment with no mapped campaign is a label, not an asset. The model that produced it has no awareness of your email platform, your ad budget, your customer service headcount, or which fields your CRM can actually filter on. It groups customers with mathematical precision. What happens next is outside its scope entirely.
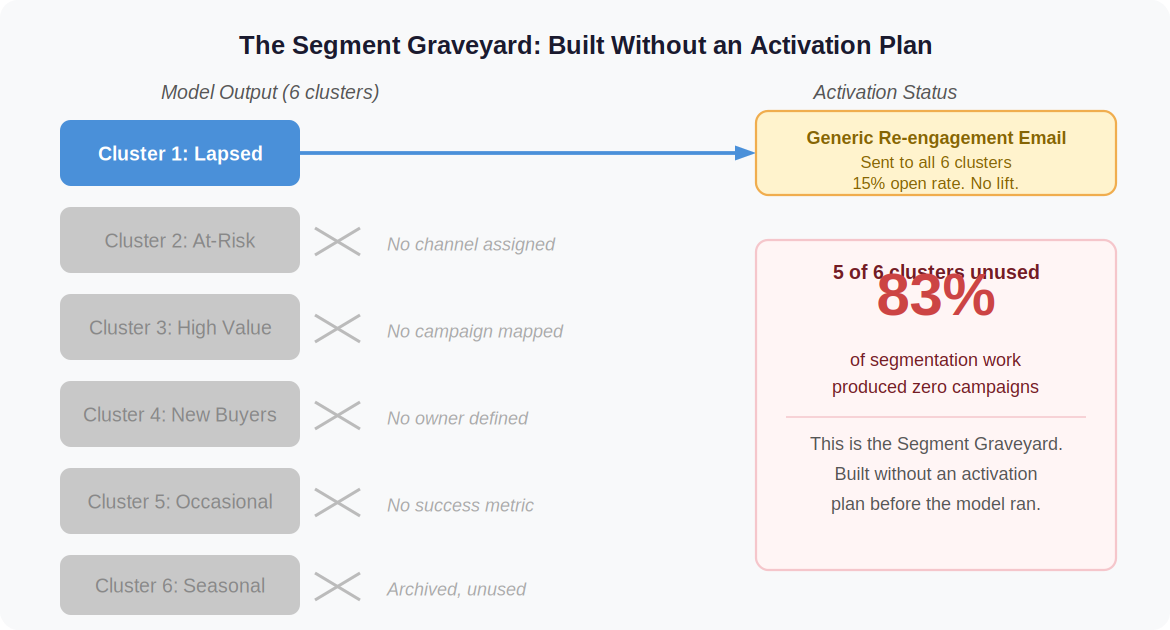
When nobody decides what happens next before the model runs, the outcome is predictable. The six clusters sit in the platform. Someone eventually schedules a generic re-engagement email to all of them because that is the nearest available campaign. The results look like every other undifferentiated re-engagement push: average open rate, average click-through, no meaningful lift. The conclusion is that AI segmentation did not work. The actual problem is that there was never a plan for what the segmentation was supposed to drive.
This accumulation of unused AI-generated clusters has a name: a Segment Graveyard. It forms when teams build audiences before deciding what to do with them. Most marketing orgs have at least one. Many have several cycles’ worth.
I ran into the clearest version of this problem while working on the ClubWest loyalty programme for Westside, one of India’s largest department store chains. The programme had 2.7 million members and generated the majority of the brand’s annual retail revenue. Every year, roughly 15% of members lapsed. When we dug into the data, we found something that made the segmentation problem specific: 73% of recent lapsers were on DND, unreachable by SMS. 63% had not opened a single email in months.
The segments existed. We knew exactly who had lapsed and in what pattern. But every activation channel we had available was hitting a wall. The segmentation was accurate. It was pointing nowhere.
The solution was not a better model. It was an activation decision that should have been made before any segmentation ran: which channels do we actually have access to for each lapsed cohort, and are those channels viable given what we know about how this group communicates?
Once we framed the question that way, the answer was clear. We built a Facebook Custom Audience from the lapsed member base and ran re-engagement directly in their social feed. No DND. No email open rate to pray over. We met them where they were. The campaign worked. It won a CMO Asia Award for Best Use of Facebook.
The lesson was not about Facebook. It was about sequence. The channel question should have been asked before the model ran, not after. That one reordering changes the entire outcome.
Understanding the scale of the lapse problem in context helps. customer churn statistics confirm that re-engagement windows are shorter than most campaign planning cycles account for. A Segment Graveyard does not just waste infrastructure spend. It wastes the time window when intervention would have worked.
Before building any segment, define its activation criteria. Four questions, answered in writing before the model runs: Which channel will this segment receive communication on? What is the specific campaign hypothesis for this group? What does success look like numerically: a reactivation rate, a conversion rate, a churn rate reduction? Who on the team owns execution? If you cannot answer all four, that segment is not in scope for this cycle.
Knowing what the failure looks like is useful. Knowing the framework that prevents it is more useful.
The Activation-First Framework: How to Build Segments You Will Actually Use
The standard workflow builds the segment and then figures out the campaign. The Activation-First Framework reverses that order.
Activation-First means you define what you will do with a segment before you build it. The model is not asked to find patterns. It is briefed to find the customers who match a campaign profile that already exists. The difference in output is significant. An open-ended brief says: find groups. An activation-first brief says: find the customers most likely to respond to a re-engagement offer via email in the next 30 days. The second brief does not produce more clusters. It produces one cluster that has a campaign waiting for it.
I learned this principle from a store analytics assignment rather than a segmentation project. When I was working on the performance framework for Titan Eye+, the brief was straightforward on the surface: some stores are underperforming. Figure out why.
The first thing I established was not a model. It was a definition: what does underperforming actually mean for a specific store, given its location, catchment demographics, and competitive density?
Without that definition, any model output was just a ranked list of stores by revenue. With it, the model produced what we called the Potential-Performance Index: the gap between what a store was doing and what it should be doing given its specific context. Same data. Completely different output. The precision came entirely from defining the question before touching the data.
Customer segmentation works the same way. Define the campaign. Then define the segment that serves it.
This is where AI personalization in marketing actually delivers on its promise: not by running sophisticated models and hoping the outputs suggest something useful, but by letting campaign intent drive the segment definition from the start.
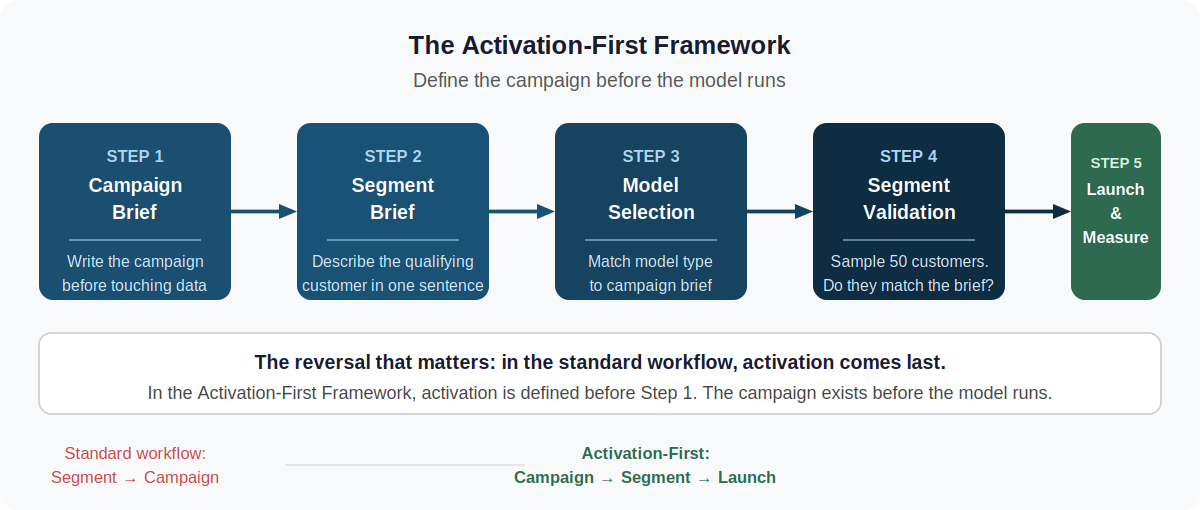
Here is the framework in sequence:
- List the campaigns you want to run in the next 90 days. Be specific: re-engagement email to customers who have not purchased in 90 to 180 days; upsell push to mid-tier buyers who have purchased in two product categories but not a third; churn-prevention outreach to subscription customers whose login frequency has dropped by more than 50% in the past 30 days. Vague campaign descriptions produce vague segment briefs.
- For each campaign, write the customer profile that qualifies in one sentence. This is your segment brief. If you cannot describe the target customer in one sentence, the brief is not specific enough to give the model useful direction.
- Choose the model type that best surfaces that profile. Re-engagement targeting based on recency: RFM. Churn prediction based on behavioral decline signals: a classification model trained on historical lapse events. Upsell targeting based on purchase breadth: a propensity model scoring cross-category purchase likelihood. The model selection follows the brief, not the other way around.
- Validate the segment output before activating. Pull a sample of 50 customers from the model’s output. Check whether they match the brief you wrote in step 2. If they do not, the data is producing something different from what you asked for. Fix the brief or fix the data. Do not launch against a segment that does not match its own description.
- Define the success metric before the campaign runs. Segment performance is not open rate. It is the specific behavioral change the campaign was designed to produce: reactivation of a lapsed customer within 30 days, upgrade from mid to high tier within the next two purchase cycles, retention of a churn-risk account past their next renewal date. Write the metric down and attach it to the segment record before anything is sent.
Choosing the Right Model for the Brief You Have Actually Written
Once you have a specific campaign brief, model selection is a matching exercise, not a technical one.
For lapsed re-engagement, where the defining characteristic is the absence of recent behavior, recency-based filtering via RFM is sufficient and is the most interpretable to stakeholders who need to approve activation spend. For churn prediction, where you are looking for early behavioral signals that precede absence, a classification model trained on historical lapse events is the right tool. For upsell targeting, where you are looking for customers whose purchase patterns suggest receptivity to adjacent products, a propensity score built on cross-category purchase history works well.
Neural network approaches add value at scale: typically 10,000 or more active customers with rich, unified behavioral signals. At most mid-market companies, they are not the right starting point. They produce outputs that are harder to validate and harder to explain to the stakeholders who control activation budgets.
Start with the simplest model that adequately fits the brief. Complexity that is not required for the task is overhead, not sophistication.
Read next: AI marketing for e-commerce
The Activation-First Framework solves the Segment Graveyard problem. But there is a second failure that happens downstream, once campaigns are running: measuring the campaign rather than measuring the segment.
Measuring Whether Your Segments Are Actually Working
Most teams measure campaign performance after a segment activates using standard metrics: open rate, click rate, conversion rate. They attribute the results to execution: the creative, the subject line, the offer, the send time. Segment performance is rarely treated as its own variable.
This creates a specific blind spot. If you do not measure whether your segments are stable, predictive, and causally connected to the outcomes they were built to drive, you cannot tell whether the AI is doing anything that a simple demographic filter would not have done. You also cannot improve the model over time. Without a feedback signal connecting segment membership to actual customer behavior, each cycle starts from the same place as the last one.
The most structured version of this problem I worked through was the churn analytics programme at TataSky, across 12 million customer records. The assignment was not just to identify subscribers at risk of lapsing. It was to understand which early behavioral signals predicted lapse at 30, 60, and 90-day windows, and whether acting on those signals within each window actually changed the outcome.
That last part is what most teams skip. Predicting churn is relatively straightforward with enough data. Knowing whether the intervention changed the predicted outcome requires a measurement structure that closes the loop between the segment’s prediction and the customer’s actual subsequent behavior. That means a holdout group, a specific behavioral metric tied to the segment’s purpose, and a reporting cycle that compares predicted outcomes against observed ones on a cadence that is short enough to act on.
Without that structure, you are reporting campaign statistics. The model gets no smarter. The segments do not improve.
Measure three things per segment, per campaign cycle: segment stability, predictive validity, and campaign lift.
Segment stability: did the customers who qualified for this segment last month still qualify this month? If a segment loses or gains more than 20% of its membership month-over-month without a corresponding change in actual customer behavior, the model is responding to data artefacts, not real behavioral shifts.
Predictive validity: did members of this segment behave as the model predicted? If a churn-risk segment predicted a 40% lapse rate and the actual observed rate was 12%, the model’s signal is weaker than the score implies and the activation threshold needs recalibrating.
Campaign lift: what was the behavioral change in the segment members who received the campaign compared to those who did not? This is the only clean measure of whether the campaign worked. Without a comparison group, you cannot separate campaign effect from baseline customer behavior.
When benchmarking your segment performance externally, apply the benchmarks at the segment level rather than the total programme level. customer retention statistics broken down by industry give you the reference point to assess whether your at-risk segment is performing ahead of or behind category norms, not just whether your overall retention rate looks acceptable.
The Holdout Group: The One Step Most Teams Skip
A holdout group is a randomly selected subset of your qualified segment audience that does not receive the campaign. Typically 10 to 15% of the segment. You track their behavior over the same window as the campaign recipients. The difference in outcome between the two groups is your actual campaign lift.
Most teams skip this because it feels like withholding revenue. If you have a churn-risk segment of 5,000 customers and hold back 500, you are not sending re-engagement to 500 people who might have stayed. That is a real short-term cost. It is also the only clean mechanism for knowing whether the 4,500 you did contact responded to your campaign or would have retained anyway.
Without a holdout, you will consistently overstate segment performance and consistently fail to improve it, because you have no signal to improve against.
Statistically significant positive difference versus holdout
Run this diagnostic against your current or planned segmentation work.
- List every segment currently in your CRM or CDP. For each one, write one sentence describing the specific campaign it is mapped to and the success metric attached to it. Any segment that cannot be described in one sentence belongs in the Segment Graveyard category and should be retired or rebuilt from a campaign brief.
- Count your qualified records before your next segmentation cycle. Customers with at least two transactions in the past 12 months. Fewer than 1,000: default to RFM and build toward machine learning clustering as your dataset grows. A clean RFM model running against 800 qualified records is worth more than a clustering model running noisily against 800 demographic shells.
- Before your next segment build, write the campaign brief first. Channel, offer, success metric, team owner. Run the model only after all four are defined in writing.
- For any segment currently in production, pull a cohort report. Are customers entering and exiting the segment as expected based on their actual behavior? A segment that is static despite the customer base changing is a sign the model is not receiving updated data or is not structured to respond to behavioral shifts.
- Run one holdout test on your next segment campaign. Hold back 10% of the qualified audience. Compare their behavior over 30 days against the 90% who received the campaign. That difference is your actual segment lift, not your estimated one.
If you want help building this framework for your specific customer data and campaign setup, reach out at shankar@shno.co.