
You turned on Klaviyo’s predictive segments. You enabled the recommendation widget. You let Meta Advantage+ run. The lift was marginal. Not enough to feel certain it was the AI doing anything. The problem is not that AI marketing is overhyped. The problem is that AI personalization requires a data threshold most stores have not crossed yet, and no guide tells you this before you build. I spent years inside customer data for retail and FMCG brands: loyalty programmes with 2.7 million members, subscriber analytics across 12 million accounts. What I know from that work is that the sequencing matters more than the tools.
AI Marketing Does Not Fail. Your Data Does.
Most ecommerce operators approach AI marketing the same way. They upgrade to Klaviyo’s paid tier, turn on predictive segments, activate the recommendation widget, and switch their ad campaigns to Advantage+ or Performance Max. Then they check the numbers a month later. Sometimes the numbers improve slightly. Sometimes they do not move at all. In both cases, the operator is left with the same question they started with: is this working?
The assumption underneath this approach is that AI marketing is a tap. Connect it to your customer data, turn it on, and it works. But AI personalization models are not taps. They are pattern-recognition systems. They need behavioral signal volume before they can identify meaningful patterns at the individual level. Without that volume, what the model produces is a statistical average: the behavior most common across the dataset, smoothed into a prediction. That prediction is almost always worse than a well-built rule-based segment, because rules encode actual human knowledge about the customer.
A rule that says “customers who bought running shoes and browsed the trail gear category twice in 30 days should receive an email about trail accessories” is smarter than a model with 200 data points. The model needs thousands of data points before it starts beating the rule. As Practical Ecommerce has documented, recommendation algorithms need interaction data before they can confidently suggest items, and new or sparse inputs leave the engine producing generic outputs rather than individual-level intelligence.
I know this because I have worked on the inside of CRM programmes with enough data to see where models start outperforming human-built segments, and enough data-sparse programmes to see where they do not. At Hansa Cequity, our team ran propensity models for some of the most data-rich programmes in the country. For TataSky, we worked with 12 million subscriber records. At that volume, predictive churn models found patterns a human analyst would have missed. But at smaller programmes, with fewer transactions per customer and shorter data histories, the models did not outperform the segment-and-trigger approach the team could build manually. Every time. Without exception.
Before enabling any AI personalization feature, run this audit. How many orders does your store process per month? How many months of behavioral event data does your email and analytics stack hold? If you are under 1,000 monthly transactions or under 12 months of clean event history, build better manual segments and lifecycle flows first. The AI features will perform when you have the data to support them. Without that foundation, you are running the model before it has anything real to learn from.
The name I use for that foundation is the Data Floor. Data Floor: the minimum volume of customer behavioral and transactional data an ecommerce store requires before AI-driven personalization produces measurable lift above well-configured rule-based segmentation.
The most useful thing that concept unlocks is sequencing. Not all AI marketing applications have the same data requirements. Some work regardless of your current volume. Others need the Data Floor in place. A third tier compounds once you are well above it.
Most ecommerce stores do not have enough data to benefit from AI personalization, and using it anyway produces worse results than a well-built segment and a well-timed email.
The Three Tiers of AI Marketing Readiness
Every AI marketing application in ecommerce fits into one of three tiers. The tier determines when to implement it, not whether to implement it. Most stores try to run all three simultaneously. That is why most stores get weak results from at least two of the three.
The stores getting strong results from AI marketing are not doing anything exotic. They are using Tier 1 tools immediately, building toward the Data Floor before activating Tier 2, and then unlocking Tier 3 once they have the longitudinal customer history to support it.
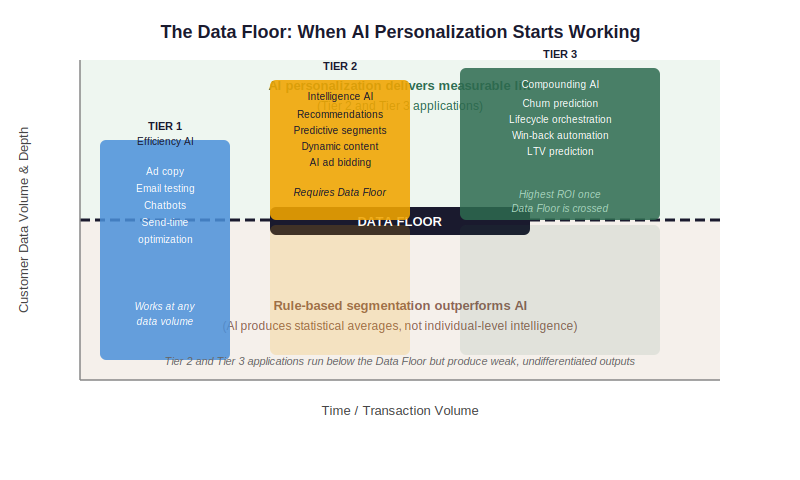
AI personalization is the topic where the Data Floor debate is most acute. Here is what the threshold looks like in practice, and what most stores are missing before they hit it.
AI Personalization in Ecommerce: What the Data Floor Means in Practice
The most common personalization implementation I see goes like this. A store activates Klaviyo’s predictive segments or Shopify’s built-in recommendation engine, points it at their order history, and considers the personalization work done. The assumption is that the platform’s AI now has everything it needs to produce relevant recommendations and targeted segments.
Order data is one behavioral signal. It tells you what customers bought. It does not tell you what they considered, what they abandoned, how long they spent on a category page, or what they searched for and could not find. A recommendation engine trained only on purchase data will do one of two things: suggest products in the same category as the last purchase (bought running shoes, now sees running socks), or surface what most similar customers bought. The first is obvious. The second is generic. Neither is personalization. Real personalization requires browse events, add-to-cart events, search queries, and session depth. Without that event layer, the model is working from a fraction of the available behavioral picture.
When I was building segmentation architecture at Hansa Cequity for the Westside ClubWest programme, the loyalty database had 2.7 million members and years of transactional history. Rich purchase data. But the behavioral event data was sparse. We knew when members bought and how much they spent. We did not know which categories they browsed without buying, or how they navigated the online properties between purchases. That gap was the reason the predictive models underperformed in their first iterations. Once we properly captured browse and category-affinity signals, the segmentation quality changed. We stopped guessing at preference from purchase alone and started reading intent directly. The AI personalization statistics show consistent revenue lift for stores that cross this threshold, but that lift requires the complete event data to feed it.
This problem is widespread. An audit of 127 stores implementing AI personalization found that 65% had fundamental data quality issues that capped their results, including inconsistent event tracking and purchase histories missing critical behavioral fields. The conclusion from that analysis was direct: you cannot personalize what you cannot measure, and you cannot measure what you have not properly instrumented.
Fix the instrumentation first. Open your Klaviyo event feed. If the only events firing are “placed order” and “viewed product,” your personalization model is half-blind. At minimum, you need product page view events with dwell time, add-to-cart events, search queries, and session depth. GA4 and Klaviyo can capture all of these. The setup is a day’s work for most stores.
Product Recommendations: The Most Visible AI Feature and the Most Frequently Wasted
Product recommendations are live in most ecommerce stores by default. Shopify’s native engine is on. A Klaviyo flow references recently viewed products. A homepage widget shows trending items. Most operators consider this personalization. It is not, yet.
A recommendation engine produces genuinely useful recommendations only when two conditions are met. First, the customer has a behavioral history deep enough to distinguish their preferences from the store’s average customer. Second, the store has enough category breadth and customer variety for the engine to produce non-obvious suggestions. If every customer who buys running shoes ends up in the same “you might also like these socks” recommendation loop, the engine is not personalizing. It is pattern-matching on the most common purchase sequence.
The fix is the same as for personalization broadly: full event instrumentation first. A customer who browses trail gear four times but only buys road shoes is telling the recommendation engine something that purchase data alone could never reveal. Once the engine can see that behavior, it stops serving the obvious and starts serving the relevant. That gap in recommendation quality is worth more than any model upgrade.
The personalization problem is a data quality problem. The ads problem is different. It is a patience problem.
AI for Ecommerce Ads: The Learning Phase Nobody Warns You About
When an ecommerce operator decides to test AI-driven advertising, the standard approach is to take a mid-performing campaign, switch it to Advantage+ or Performance Max, run it for two to four weeks, and compare results to the previous period. If ROAS drops, the conclusion is that AI ads do not work. If ROAS holds flat, the conclusion is that AI is no better than manual. The test is considered complete.
Both conclusions are wrong, because both are drawn from the wrong phase of the campaign.
Meta Advantage+ and Google Performance Max start from zero and learn from every conversion event that comes in. During the first two to four weeks, the algorithm is in what Meta calls the learning phase. During this period, it is deliberately broad. It tests audiences and placements it would not use in a mature, optimized state. CPMs during the learning phase are often higher. ROAS is often lower. This is not the AI failing. It is the AI gathering the signal it needs to stop failing. Operators who pause campaigns in week two are pausing exactly when the model is most data-hungry and least optimized. They never see what the mature model can do.
I have seen this pattern consistently in advisory work, including at KoinX, a crypto tax SaaS with over 1.5 million users. The category has low conversion volumes relative to traffic. Compliance-driven conversions do not happen at the frequency of an apparel checkout. When we ran Advantage+ campaigns for acquisition, the first three weeks consistently looked worse than the preceding manually managed campaign. Same budget. Better creative. Worse numbers. By week five or six, the ROAS had moved past the manual campaign’s performance. The learning phase looked like failure. The mature model looked like a different product entirely. The AI advertising statistics document this performance gap between learning-phase and mature-model AI campaigns. The spread is not small.
Meta’s own guidance recommends roughly 50 conversion events per ad set per week for the delivery system to optimize predictably. That volume gives the algorithm enough data to exit the learning phase and start refining its audience model. Below that threshold, the campaign remains in a state of active exploration rather than optimization.
Before switching any campaign to AI-driven bidding, check your monthly conversion volume. If you are driving fewer than 50 conversion events per week per campaign, the model will take longer to exit the learning phase and the cost of that phase will be higher. Run a 30-day parallel test instead: your existing manual campaign alongside a new Advantage+ campaign at a smaller budget. Let the AI model accumulate data in a lower-stakes environment before you commit the full budget.
When to Trust Advantage+ and When to Override It
Once a campaign has cleared six weeks, three signals tell you whether the AI model is working or still finding its footing:
- ROAS is trending upward week-over-week. A mature AI campaign should show directional improvement as the model refines its audience understanding. Flat ROAS after six weeks suggests insufficient conversion volume for the model to learn from.
- The effective audience is narrowing. In the learning phase, Advantage+ targets broadly. As it matures, the audience concentrates toward your higher-converting segments. If targeting is still scattershot at week five, the model has not found a repeatable pattern yet.
- CPM is coming down. The broad exploration of the learning phase is expensive. A model that has found its audience bids more efficiently on a narrower set of placements.
If all three are moving in the right direction, trust the model and resist the urge to narrow targeting manually. If two or more are still stalled at week six, the campaign likely lacks the conversion volume for the AI to work. Supplementing with manual remarketing as a parallel pathway can help. The remarketing statistics show that AI-optimized retargeting and standard remarketing reach meaningfully different audiences. Running both is not redundant.
Personalization requires instrumentation. Ads require patience and conversion volume. Retention requires neither. It requires something you already have.
AI for Ecommerce Retention: Where the ROI Is Actually Hiding
Almost every AI marketing guide sequences acquisition first. Use AI to find new customers more efficiently, personalize their first visit, optimize the funnel. Retention follows as the downstream consequence. This sequencing feels logical. It is also backwards for most stores.
Retention AI works on a dataset that is qualitatively different from acquisition data, and qualitatively better for any store with meaningful history. It works on known customers with longitudinal behavioral records. The customer who bought twice in the first three months, then disappeared. The subscriber who opened every email for six months, then went silent after a price increase. The repeat buyer whose purchase frequency dropped for the first time in two years. These patterns are readable by an AI model well before you have enough new-visitor data to make acquisition AI meaningful. A store with 500 monthly orders and three years of customer history has a richer AI retention dataset than it has an acquisition dataset. The customer retention statistics consistently show that revenue from retained customers outperforms equivalent acquisition spend, and the compounding effect widens over time.
The clearest demonstration I have seen of this was at Hansa Cequity, working on the Westside ClubWest loyalty programme. The programme had 2.7 million members. Every year, around 15% of them lapsed. When the CRM team dug into the lapsed base, two things stood out: 73% of recent lapsers were on DND and unreachable by SMS. 63% had not opened a single email in months. The blunt move was to run a win-back campaign to the entire lapsed cohort. The smarter move was to identify which members in that base were actually winnable.
We used frequency, recency, spend trajectory, and category breadth to build a propensity score across the lapsed cohort. The model identified a subset that had lapsed recently, had bought across multiple categories, and had significantly higher AOV than the average lapser. That subset converted on win-back campaigns at a substantially higher rate than the full lapsed base. We spent less on intervention and recovered more revenue than the broadcast approach would have.
The economics of this approach are supported by broader research. According to Bain and Company, a 5% improvement in retention can lift profits by 25 to 95%, and AI lifecycle orchestration tools consistently drive two to three times the ROI of static broadcast campaigns when applied to scored retention segments. Acquiring a new customer costs 5 to 25 times more than retaining one. The data advantage of working on existing customer history, rather than cold acquisition data, compounds that ROI further.
The data for this kind of work already exists in your Shopify account or your Klaviyo analytics. Most stores are sitting on a winnable lapsed cohort while running paid campaigns to find new customers.
Pull your lapsed customer segment. Filter for customers who purchased at least once in the last 24 months but have not returned in the last 90 to 180 days. Build a basic score using four inputs: recency of last purchase, purchase frequency, average order value, and category breadth (how many distinct product categories they bought across). Klaviyo’s predictive analytics, Braze, or even a manually scored segment in a spreadsheet can do this. Identify the top 20% of the lapsed cohort by score. Run your win-back sequence to that segment first.
The Win-Back Model: Where AI Retention Produces the Fastest ROI
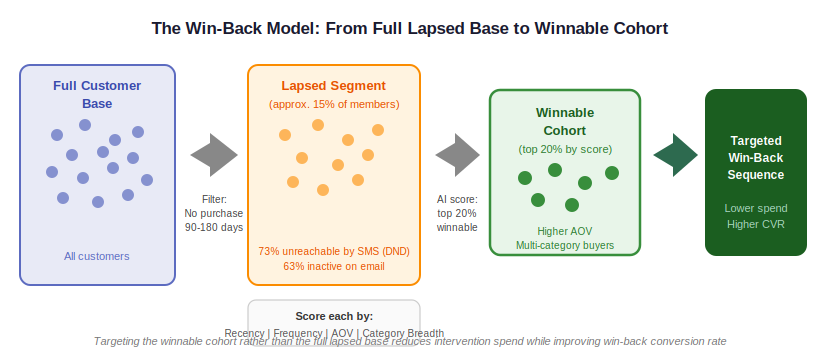
The win-back model is the fastest AI retention application to build for one reason: the data it needs already exists. You do not need a CDP. You do not need a full behavioral event layer. You need purchase history, which every ecommerce store has.
Here is the minimum viable version. In Klaviyo or your preferred platform, create a segment of lapsed customers using three filters: last purchase date more than 90 days ago, at least two previous purchases, and at least one email opened in the last 12 months. That last filter matters. If they opened at least one email recently, they are reachable. Now apply a manual score: purchase frequency multiplied by average order value, divided by days since last purchase. Customers with the highest scores are your winnable cohort. Run your win-back sequence to them. Not to the full lapsed base.
The lifecycle email statistics show the benchmark performance gap between a generic win-back broadcast and a scored, targeted win-back sequence. The conversion rate difference is not marginal. When you combine it with the reduced cost of targeting a smaller, better-qualified segment, the ROI from this single AI retention application is often higher than anything a store will see from its personalization or ad AI for the first several months.
The right question is not whether to use AI marketing. Every platform you already pay for has AI features built in. The question is whether you are at the right stage to use them effectively.
Here is how to find out.
- Audit your monthly transaction volume. If you are under 1,000 orders per month, invest the time in building better manual segments and lifecycle flows before enabling AI personalization features. The Data Floor is real. The AI features will still be there when your volume supports them.
- Check your behavioral event instrumentation. Open your Klaviyo event feed or analytics platform. If the only events firing are “placed order” and “viewed product,” your event layer is incomplete. Instrument browse events, add-to-cart events, and search queries before activating predictive segments or recommendation engines.
- Review your ad campaign conversion volume. If you are driving fewer than 50 conversions per week per campaign, do not switch entirely to AI bidding yet. Run a 30-day parallel test with a smaller AI campaign budget alongside your existing manual campaigns. Let the model accumulate data before you hand it the full budget.
- Pull your lapsed customer segment today. Customers who purchased in the last 24 months but have not returned in the last 90 to 180 days. Build the basic win-back score using frequency, AOV, recency, and category breadth. Run the sequence to the top 20%. This is the fastest ROI available to you from AI marketing, and you can start it without any new tools.
If you want help auditing your AI marketing setup or building out any of these applications, reach out at shankar@shno.co.