
You hired an AI writing tool. You built a review process. You still spend 3 hours editing every draft that was supposed to take 20 minutes to produce. The problem is not your review process. The problem is your brief. I run SEO and content strategy for a SaaS platform with over 1.5 million users, and I built a no-code content community that pulled in 50,000 monthly readers with zero paid acquisition. The teams that actually scale content production with AI all made the same fix before they scaled: they fixed the brief first.
The Reason Your AI Drafts Keep Needing Full Rewrites
Most teams find the problem at the output stage. The draft is generic. The tone has drifted from the brand. The argument, if there is one, is thin and forgettable. So the response is more review: an extra editing pass, a tighter checklist, a second pair of eyes on every piece. Some teams bring in a dedicated AI editor. The problem is correctly identified. It is incorrectly located.
A draft built on a weak brief cannot be efficiently edited into good content. What you are doing when you edit that draft is not refinement. It is reconstruction. You are adding the argument that should have been in the brief. You are inserting the differentiation signal that should have been in the brief. You are providing the specific proof that should have been in the brief before the AI touched the file. Every hour spent recovering missing inputs at the edit stage is an hour that produces nothing new. That relationship does not improve with more review steps. It only changes when the brief quality changes. Teams that build more elaborate review processes for weak AI drafts are not solving the scaling problem. They are funding it.
According to AI content marketing statistics for 2026, AI adoption for content creation is now near-universal among marketing teams. Most of those teams are producing more content. A significant portion of them are spending more time editing it. Adoption solved the volume problem. It introduced quality debt. And quality debt grows faster than review processes can absorb it.
According to Conductor’s 2026 AEO/GEO CMO Investment Report, a survey of more than 250 enterprise executives, scaling AI-optimized content ranked as the top challenge C-suite leaders cited across their content programs. The investment is in volume. The brief stays weak.
What the Google algorithm impact data confirms is what happens when teams scale volume without fixing the upstream inputs. Sites publishing high volumes of undifferentiated AI content saw 60-80% traffic drops following the March 2026 core update’s enforcement of scaled content abuse policies. Google does not penalize AI-generated content. It penalizes content that has no differentiating inputs. The brief is where differentiating inputs enter. Without them, you are scaling content that Google is actively learning to discount.
The AI content scaling problem is not a review problem. It is a brief problem. Building a better review queue for weak AI drafts is the same as hiring more inspectors at a factory that keeps making defective products.
Stop diagnosing the problem at the draft stage. The draft is not the product. The brief is. What belongs in a brief that actually works is a different question from what most teams have been told.
What Goes Into an AI Brief That Actually Works
The brief most teams use looks like this: target topic, primary keyword, audience type, word count, tone, and a list of sub-topics pulled from competitor research. Sometimes a formatting note. This is not a brief. It is a format instruction. It tells the AI what to produce and how long to make it. It does not tell the AI what to argue.
A format instruction gives the AI zero information it cannot find by searching the internet itself. The output will be a structurally correct article built from publicly available information in a standard format. It will look like every other article on the same topic produced from a similar format instruction. That is not a coincidence. It is the expected result when inputs are interchangeable.
The reason most AI-assisted content in a category starts looking identical across competitors is not that the tools are indistinguishable. It is that the briefs are. The brief is the one place where differentiation either enters the article or does not. There is no other place.
The Difference Between a Topic and an Argument
A topic is what the article is about. An argument is the specific claim the article makes and can prove. “Content marketing” is a topic. “Most content marketing fails because teams measure reach instead of decision-influence” is an argument.
AI can write endlessly about a topic. It needs a human to supply the argument. This is the single most common brief failure. Teams produce thorough format instructions and call them briefs. The AI produces an article about the topic with no argument. The editor tries to add the argument during review. It takes three times as long as it should, because the argument has to be reverse-engineered into content that was structured around its absence.
Brief-First Scaling is the practice of treating brief construction as the primary skilled work in an AI content workflow, rather than draft review. Under Brief-First Scaling, the AI does not generate the argument. It receives the argument and builds toward it.
I run SEO and content strategy for KoinX, a crypto tax SaaS with 1.5 million users. The category is crowded. Regulatory language is nearly identical across competitors. The first content briefs I worked with on that engagement were standard: keyword, audience, word count, tone, and a competitor-derived sub-topics list.
Average editing time per article: approximately two and a half hours.
The switch that changed the output was not a different AI tool. It was a brief format that required the writer to state one thing before any drafting began: the specific argument the article would make. Not the topic. The argument. The claim that could be proved and differentiated. Three other required elements came alongside it, which I will cover below.
Average editing time after the switch: under 45 minutes.
Same AI tool. Same writer. Different brief.
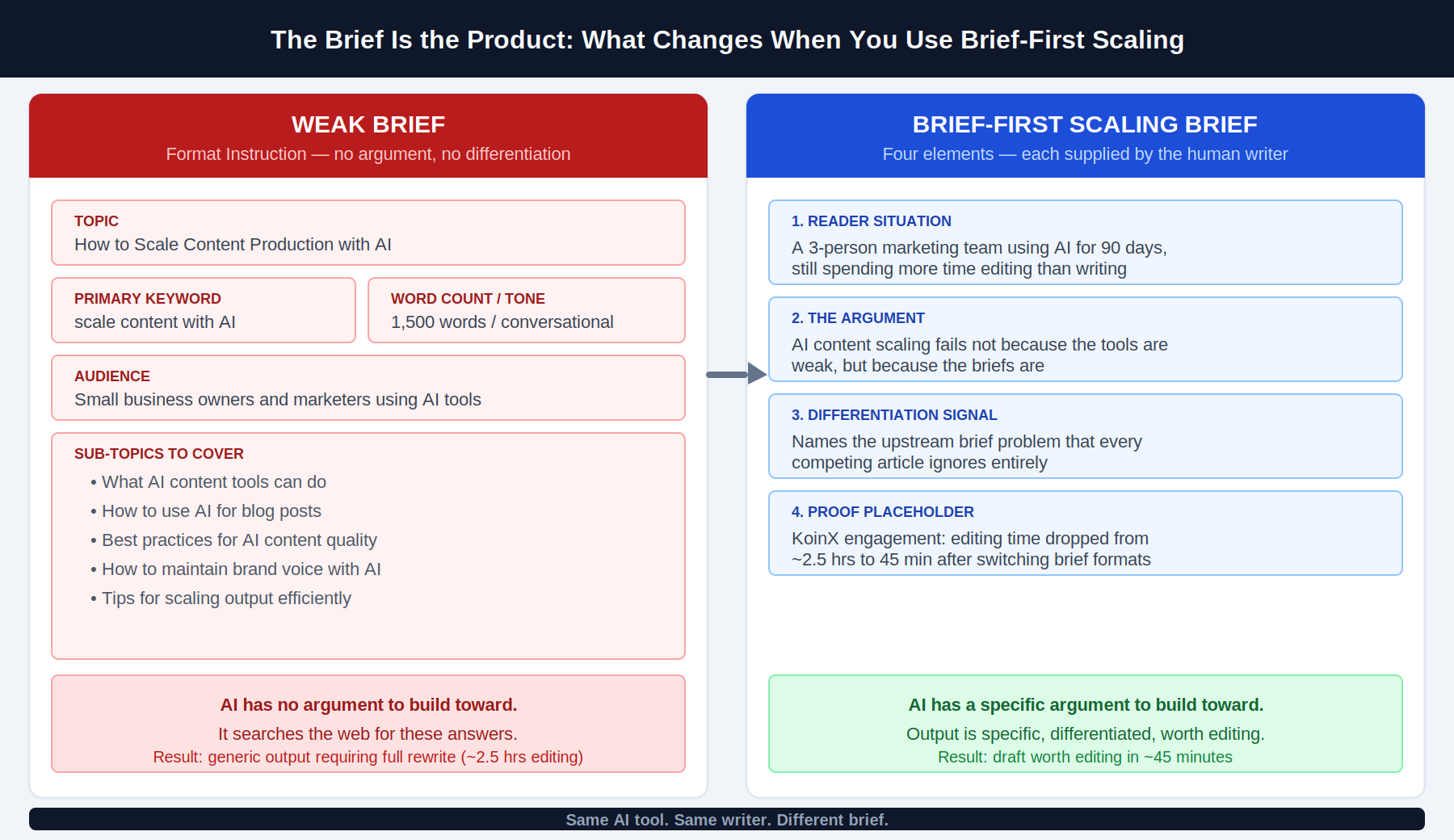
The four elements that separate a Brief-First Scaling brief from a format instruction:
Reader Situation. Not a demographic description. The specific situation the reader is in when they find this article. “A 3-person marketing team that has been using AI for 90 days and is still spending more time editing than writing” is a reader situation. It changes what the article says, how it opens, and which examples land. Without it, the AI writes for everyone. Content written for everyone connects with no one.
The Argument. One declarative sentence stating the claim this article makes that can be proved. If you cannot write the argument in one sentence before briefing the AI, the brief is not ready. This element is also where brand voice actually lives in practice: not in a separate style guide sitting outside the brief, but in the specific position this brand takes on this specific topic. What does this brand believe about this question? State it as an argument.
The Differentiation Signal. What does this article say that the current top three results do not? This element forces the writer to do the competitive read before briefing, not after. If the answer is nothing, the brief is not ready. Writing the differentiation signal is often the most uncomfortable step. It requires having a position before you know whether the AI can execute it. That discomfort is the point.
The Proof Placeholder. What specific data, experience, or named source anchors the central claim? If the answer is “the AI will find something,” the brief is not ready. The AI will find something plausible. Plausible is not differentiated. This is the slot where first-hand experience goes: what I found working with a retail loyalty programme of 2.7 million members, what failed on a BFSI campaign I ran, what surprised me when I tested a specific tool for Shnoco. If no proof placeholder exists, acknowledge it before briefing. Either find one or classify this article as human-led.
Read next: how AI content generation works, for a closer look at the mechanism this brief-building process is designed to direct.
The brief system handles most content types well. Not all of them. Knowing which ones to pull out of the AI workflow entirely is what keeps the quality floor from collapsing.
The Content Types That Should Not Be AI-Drafted
The natural response to a working brief system is to apply it everywhere. Same process, same template, all content types. Blog posts, email newsletters, thought leadership, case studies, opinion pieces, product comparisons. This works for most formats. For three specific content types, it consistently produces content that is structurally correct and practically useless.
The value of certain content types comes entirely from first-hand experience, genuine opinion, or real-case specificity. None of these can be generated by the AI. The AI can produce a case study that sounds like a case study. It cannot produce a case study containing the actual client name, the actual problem, the actual number that changed, and the moment the team figured out what was wrong. Without those specifics, the case study is structurally familiar and authorially empty. A reader evaluating whether to trust the author gets nothing that a generic content producer could not have written. The structure exists. The authority does not.
The same applies to thought leadership and opinion pieces. AI can structure an argument. It cannot own one. It cannot have been in the room where the decision was made and know exactly why the consensus was wrong.
Lily Ray, who has tracked Google algorithm impact systematically across hundreds of sites, documented multiple cases of sites losing all search visibility overnight following aggressive AI scaling strategies. The consistent pattern across penalized sites: high volume, structurally correct content, no first-hand experience signal. The 60-80% traffic drops from the March 2026 update confirm the enforcement reality. Content type did not protect those sites. The absence of genuine first-hand input condemned them.
Building Shnoco to 50,000 monthly readers confirmed the same dynamic from the other direction. Every piece that compounded over time was written from direct evaluation: personally tested tools, specific tradeoffs I had actually encountered, use cases I had actually built. The pieces that disappeared from search were the ones where the brief was thin and the writing was structure without experience. The format did not determine the outcome. The presence or absence of genuine input did.
Three content types to remove from the AI drafting queue regardless of team size or deadline pressure:
Thought leadership and opinion pieces. The argument requires a specific, defensible position from someone with relevant experience and actual stakes in the answer. A well-structured opinion from nobody in particular is not thought leadership. It is content shaped like thought leadership. Readers can tell the difference. Search engines increasingly can too.
Case studies and client stories. The specifics that make a case study credible can only come from the person who was in the situation. AI will produce plausible specifics if you do not provide real ones. Plausible specifics in a case study are fabrications. The AI does not know this. The reader eventually will.
Content making original claims or research-backed assertions. If the data or research is not explicitly in the brief, the AI will produce plausible-sounding figures that may or may not correspond to anything real. This is not a theoretical hallucination risk. It is a practical one: a quietly invented percentage in a paragraph that sounds authoritative. For YMYL content categories, this is not a quality issue. It is a liability issue.
The definition of AI-assisted versus AI-generated content is simpler than most guides make it. AI-assisted: a human with specific knowledge provides the inputs, arguments, and proof; the AI structures, drafts, and compresses time. AI-generated: the AI provides everything from publicly available information, with no genuine human input in the brief. The difference is brief quality. There is no other meaningful line.
With the brief system in place and the right content types identified, the question that remains is how to add volume without losing what you have built.
How to Go From 4 Posts to 20 Without Breaking Your Quality Standard
The most common scaling attempt: try to 10x output across all content types at once. Brief everything the new way, add more pieces per week, run a review pass on each one. Within two to three months, one of two things happens. Either the review volume creates bottlenecks that negate the efficiency gains. Or the quality drift goes undetected until an algorithm update or a reader complaint makes it visible.
The problem is not effort. It is sequencing.
A quality standard that exists only in an experienced editor’s head cannot survive the handoff to AI at volume. It degrades because every new piece gets evaluated slightly differently. The bar moves week by week. Six months in, the content looks nothing like it did when the process was working. The Brief-First Scaling system holds at volume only if the quality standard is written down before the first piece using the new process is published. Written down means a specific rubric that a person who has never seen the brand before could use to evaluate a piece and reach the same conclusion an experienced editor would.
The sequence I have seen hold across every content operation I have helped scale: one content type first, one brief template tested on three to four pieces before it is locked, a quality rubric written before scaling begins, then volume added incrementally. Teams that skip the rubric step produce consistent volume for eight to twelve weeks and then hit a quality cliff when the founding editor gets stretched across too many reviews or someone new joins the process. The rubric is what holds when the key person is unavailable.
Publishing one well-briefed piece and repurposing it across secondary formats produces better returns per hour than producing five thin standalone pieces, as the content repurposing performance data shows across ROI uplift and reach benchmarks.
Before scaling, check the content performance benchmarks to set a baseline for the metrics the new volume will be measured against. The answer to “is this working?” needs to exist before the volume goes up.
The four-step sequence for teams scaling from 4 posts per month to 20:
Step 1: Pick one content type. Start with the format where you already know what good looks like. You need to be able to evaluate AI output against a standard you can state in three sentences. If you cannot do that for a given format, pick a different one to start with.
Step 2: Build and test one brief template for that content type. Use the four-element structure: reader situation, argument, differentiation signal, proof placeholder. Run it on three pieces. Edit the template as you learn. Lock it only when the output is consistently worth editing rather than rewriting.
Step 3: Write the quality rubric before you scale. Not after the first bad piece appears. Four criteria: argument specificity, differentiation signal presence, factual accuracy, brand voice alignment. Score each one to five. Set a minimum passing score per piece before it enters the review queue. A piece that scores below the minimum goes back to the brief stage, not into a longer editing session.
Step 4: Add volume one piece at a time. When the system is stable at the new volume, add another content type and repeat the full sequence from Step 1 for that type. Scaling across multiple content types simultaneously before any single type is stable is the fastest route to quality drift.
Where to Start Today
- Pull the last three AI drafts you edited. Note how long each one took. If any took longer than 45 minutes, that piece had a brief problem, not a draft problem.
- Write the argument for your next article before you write the brief. One declarative sentence stating the specific claim this article makes that can be proved. If you cannot write it, the brief is not ready.
- Answer the differentiation signal question before you brief the AI: what does this article say that the current top three results do not? Write the answer in the brief explicitly.
- Identify one content type on your current calendar that should be human-led: a thought leadership piece, a case study, or an article making an original claim. Remove it from the AI drafting queue.
- Write your quality rubric before adding volume. Four criteria, scored one to five, with a minimum passing score per piece. Have it written before the first Brief-First Scaling article publishes.
If you want help building the brief system for your specific content type, reach out at shankar@shno.co.